Since most people are doing a year summary, I thought I should do one. Then I remembered that I can barely remember what I did yesterday (for example today I went in to work only to discover it was a Saturday...). So instead I'm going to try and predict what I'll do in 2007, with the proviso that it's a complete pile of fiction, but some of it might actually happen.
PhD + Catch
2007 should be the year I complete my PhD. Its certainly the last year I get any funding for my PhD. With aiming to complete my PhD, I also want to release a really good version of Catch - the Hsakell pattern match checker. I've been working away on this for over 2 years now, so would like something I can point at. I'm hoping Catch will be out by March, but I realise I said "a few months" at least 9 months ago now - it turns out the Halting Problem is quite hard...
Hoogle 4
I think Hoogle 4 has been knocking around for about 8 months now. I'd actually like to get this finished, and be the main version of the website. This brings just a complete polishing of Hoogle. Hoogle seems to be a well used tool, and hopefully Hoogle 4 will just make it better at everything and much more reliable.
Yhc
One project which I really want to polish off and put a release out of is Yhc. Yhc has lots of really exciting features, and is evolving pretty fast. The Yhc Javascript stuff is particularly interesting - the demos just keep getting better and better. The Yhc.Core side of things is looking really impressive. My optimisations stuff is starting to look really good. If I ever finish WinHaskell, Yhc might become a very nice choice for the default compiler.
Parsing
I really really want to finally implement my parser. Unfortunately, just taking a look at the things above this makes that rather unlikely. If you add in distractions like Hat, WinHaskell, WinHugs etc then it looks a lot less likely. As such I'm going to make the target to formalise my state machine algorithms and write a state machine library in Haskell which I can use as the basis for my parser.
I've tried to keep this list as short as possible, to actually give me a chance of doing some of it. We'll see if that happens.
Saturday, December 30, 2006
Saturday, December 23, 2006
Hoogle Progress, HsMan features
About 2 months ago Frederik Eaton posted "HsMan" to the ghc list, a program that with one command line could look up the documentation for a function. Now Hoogle 4 has that feature :)
$ hoogle +filepath combine /info /doc
System.FilePath.Version_0_09.combine :: FilePath -> FilePath -> FilePath
Combine two paths, if the right path isAbsolute, then it returns the second.
Posix: combine "/" "test" == "/test"
Posix: combine "home" "bob" == "home/bob"
Windows: combine "home" "bob" == "home\\bob"
http://www-users.cs.york.ac.uk/~ndm/projects/filepath/System-FilePath-Version_0_09.html#v%3Acombine
What the above says is search the filepath module for the name combine, and when you find it, with the one that ranks best, display the haddock entry for it (info) and a link to further documentation (doc)
It was a reasonable amount of work to add, but there is a good reason for adding this feature, which will become clear when Hoogle 4 web version is relased :)
$ hoogle +filepath combine /info /doc
System.FilePath.Version_0_09.combine :: FilePath -> FilePath -> FilePath
Combine two paths, if the right path isAbsolute, then it returns the second.
Posix: combine "/" "test" == "/test"
Posix: combine "home" "bob" == "home/bob"
Windows: combine "home" "bob" == "home\\bob"
http://www-users.cs.york.ac.uk/~ndm/projects/filepath/System-FilePath-Version_0_09.html#v%3Acombine
What the above says is search the filepath module for the name combine, and when you find it, with the one that ranks best, display the haddock entry for it (info) and a link to further documentation (doc)
It was a reasonable amount of work to add, but there is a good reason for adding this feature, which will become clear when Hoogle 4 web version is relased :)
Friday, December 22, 2006
Hoogle 4 progress
I'm slowly working through the things I want for Hoogle 4, and its coming along quite nicely. A quick tour of the features I've already implemented:
Easier generation of Hoogle Databases
First create a Hoogle file using Haddock and Cabal:
> runhaskell Setup haddock --hoogle
Then convert it to a Hoogle binary database:
> hoogle /convert=base.txt
This will produce base.hoo, an optimised Hoogle database.
Faster text searches
Most searches are text searches, they used to linearly scan through the data, now they build a nice efficient index and hop directly to the relevant bit. This makes text searches over 100 times faster, and means they scale linearly with the number of results and the size of the text, rather than previously where they scaled with the size of the database.
As a result of having faster searches, I can now do multi-word searches, searching for two different words, and then matching between them. i.e. you can now search for "concat map" (or "map concat") and get concatMap returned.
Proper API
There is now a proper Hoogle API, which the Hoogle command line tool and web tool call out to. This will hopefully people can layer new things on top of Hoogle more easily.
Multiple package searching
You can now search within multiple packages at a time. For example "drop +base +filepath" will search both the base and filepath modules, as though they were one.
Restricting on module name
As requested you can now restrict searches by module name, for example "Prelude.map" and "map +Prelude" will both do a search for the map function that resides in the Prelude.
Proper parsing
The parser is written in parsec now, much more reliable! And also much better error messages, hopefully this should make it easier to extend Hoogle in the future as well.
The Future
I broke quite a lot with the complete revamp of the code, so the idea is to fix up what I broke and try and push a new release out relatively soon.
Easier generation of Hoogle Databases
First create a Hoogle file using Haddock and Cabal:
> runhaskell Setup haddock --hoogle
Then convert it to a Hoogle binary database:
> hoogle /convert=base.txt
This will produce base.hoo, an optimised Hoogle database.
Faster text searches
Most searches are text searches, they used to linearly scan through the data, now they build a nice efficient index and hop directly to the relevant bit. This makes text searches over 100 times faster, and means they scale linearly with the number of results and the size of the text, rather than previously where they scaled with the size of the database.
As a result of having faster searches, I can now do multi-word searches, searching for two different words, and then matching between them. i.e. you can now search for "concat map" (or "map concat") and get concatMap returned.
Proper API
There is now a proper Hoogle API, which the Hoogle command line tool and web tool call out to. This will hopefully people can layer new things on top of Hoogle more easily.
Multiple package searching
You can now search within multiple packages at a time. For example "drop +base +filepath" will search both the base and filepath modules, as though they were one.
Restricting on module name
As requested you can now restrict searches by module name, for example "Prelude.map" and "map +Prelude" will both do a search for the map function that resides in the Prelude.
Proper parsing
The parser is written in parsec now, much more reliable! And also much better error messages, hopefully this should make it easier to extend Hoogle in the future as well.
The Future
I broke quite a lot with the complete revamp of the code, so the idea is to fix up what I broke and try and push a new release out relatively soon.
Thursday, December 21, 2006
Will produce patches for PhD
I've just got back to my home, and am doing darcs pull's against all the repo's around to get my work up to date. I noticed Yhc has over 1000 patches, and then I pulled my primary PhD repo - and found I have 1626 patches! I have at least 100 more in a separate repo I use for one chunk of the code, and was working in CVS for over a year before moving to Haskell.
The Darcs repo for my PhD at home seemed dead, so I did a fresh darcs get, no checkpoints. It takes a while...
The Darcs repo for my PhD at home seemed dead, so I did a fresh darcs get, no checkpoints. It takes a while...
Friday, December 15, 2006
Advertising Haskell
A lot of posts on the mailing list at the moment seem to be about how we can promote Haskell to a greater audience. The idea of this post is to figured out why we might want to promote Haskell to a greater audience, which I think will give us a clue where to go. If Haskell was more popular then:
Of course, there are also downsides to Haskell being more popular:
So, question, do we want Haskell to be more popular. At the moment I quite like the fact that when programming I can be much faster than other people, and have far fewer errors. It would however be nice if I could get a job doing Haskell at some point, rather than becoming a C monkey once more, which will be doubly painful after experiencing so much Haskell.
My personal view on how Haskell can be made more popular:
In my opinion, we do plenty of advertisments already. There is not nearly enough coding going on, Cabal could benefit from extra contributors, I know Yhc could etc. When the tools are ready the users will come, and then if they don't come naturally, we can prod them. Until that time the steady flow of new users is plenty.
- More Haskell jobs would emerge
- People would find it easier to introduce Haskell in a work place
- Less C in the world
- More reliable software
- Elegance and beauty
Of course, there are also downsides to Haskell being more popular:
- Bigger communities aren't always as friendly
- Commercialisation will loose some benefits of Haskell (open source etc.)
- The volume of beginners will outweigh the experienced professionals
- Managers might push Haskell for entirely unsuitable things
So, question, do we want Haskell to be more popular. At the moment I quite like the fact that when programming I can be much faster than other people, and have far fewer errors. It would however be nice if I could get a job doing Haskell at some point, rather than becoming a C monkey once more, which will be doubly painful after experiencing so much Haskell.
My personal view on how Haskell can be made more popular:
- Remove features, generalise features, do not add features. I don't understand/know rank-n types, template Haskell, GADT's, impredictive polymorphism, arrows... Beginners don't want to know either! Getting the features right is good, which may mean adding features, but not necessarily.
- Continue to be polite and helpful
- Promote Haskell as a programming course
- Promote Haskell to experienced programmers looking for something new
- DO NOT promote Haskell in industry, if you force this on to people, they'll just discover we are not ready for this yet!
In my opinion, we do plenty of advertisments already. There is not nearly enough coding going on, Cabal could benefit from extra contributors, I know Yhc could etc. When the tools are ready the users will come, and then if they don't come naturally, we can prod them. Until that time the steady flow of new users is plenty.
Monday, December 11, 2006
bhc: Basic Haskell Compiler
I have been thinking Compilery thoughts for a while now, so I thought I'd jot them down. I am starting the "bhc" project here and now! The intention is that bhc will be a concept, and some thoughts, for at least another year - definately not anything as concrete as code!
The current Haskell compilery things are:
What I would like to do is create a new front end for Yhc, taking the Yhc.Core and Yhc.ByteCode bits as they stand, and replacing the front end. I'd also like to base the entire code on libraries, rather than compiler passes, and make everything entirely reusable. I also want to aim for simplicity, elegance and readability.
So, first things first. Haskell is really the only language to implement this in. After that you have a few stages until you get to the Yhc.Core language:
There is only one way to write a parser, using my parsing system (not finished, barely even started). There is only one way to write a type checker, using my type checker generator (not started at all, barely even specified, not even a link, definately not proven!). Name resolution isn't that hard. Dictionary desugaring should use the special method of Catch (same as Jhc, I believe). Desugaring is trivial with Play classes (warning, if you follow that link, not finished!), I also want to have invertable desugaring, for analysis purposes. The parsing and typechecking would be standalone libaries.
Two of these things need to be written first, but thats part of the fun :)
Note that type checking does all the typey stuff, dictionary desugaring uses the types. Nothing else uses types, and in fact, I think this compiler should be untyped. (I know no one will agree with me, all I can say is that I think I'm right, but realise everyone thinks I'm wrong)
The next big decision is file formats: I would like to have a .bho (basic haskell object) file which corresponds to a single module, and a .bhl (basic haskell library) which is a whole library, and a .bhx (basic haskell executable) which is a whole program. Inside a .bho you would have (all items are optional):
A .bhl would have those three things, but linked together within a library. A .bhx would have all of that, including all the libaries, linked in as one.
I would also write an optimser, for whole program analysis, which took a .bhx, and produced an equivalent one. Probably also a compiler to C code, for super-fast execution.
So what in this compiler would be new?
So, who wants to have some fun?
The current Haskell compilery things are:
- Hugs - fast to compile, slow to run
- GHC - slow to compile, fast to run
- Yhc/nhc - medium at both
- Jhc - aiming for super slow to compile, super fast to run
- ...
What I would like to do is create a new front end for Yhc, taking the Yhc.Core and Yhc.ByteCode bits as they stand, and replacing the front end. I'd also like to base the entire code on libraries, rather than compiler passes, and make everything entirely reusable. I also want to aim for simplicity, elegance and readability.
So, first things first. Haskell is really the only language to implement this in. After that you have a few stages until you get to the Yhc.Core language:
- Make (Cabal should do this)
- Parsing
- Name resolution
- Type checking
- Dictionary desugaring
- Desugaring
There is only one way to write a parser, using my parsing system (not finished, barely even started). There is only one way to write a type checker, using my type checker generator (not started at all, barely even specified, not even a link, definately not proven!). Name resolution isn't that hard. Dictionary desugaring should use the special method of Catch (same as Jhc, I believe). Desugaring is trivial with Play classes (warning, if you follow that link, not finished!), I also want to have invertable desugaring, for analysis purposes. The parsing and typechecking would be standalone libaries.
Two of these things need to be written first, but thats part of the fun :)
Note that type checking does all the typey stuff, dictionary desugaring uses the types. Nothing else uses types, and in fact, I think this compiler should be untyped. (I know no one will agree with me, all I can say is that I think I'm right, but realise everyone thinks I'm wrong)
The next big decision is file formats: I would like to have a .bho (basic haskell object) file which corresponds to a single module, and a .bhl (basic haskell library) which is a whole library, and a .bhx (basic haskell executable) which is a whole program. Inside a .bho you would have (all items are optional):
- Full original source code to the module
- Desugarred source code, in Yhc.Core format
- Bytecode, in Yhc.ByteCode format
A .bhl would have those three things, but linked together within a library. A .bhx would have all of that, including all the libaries, linked in as one.
I would also write an optimser, for whole program analysis, which took a .bhx, and produced an equivalent one. Probably also a compiler to C code, for super-fast execution.
So what in this compiler would be new?
- Focus on libraries, Yhc.Core, Yhc.Parse, Yhc.ByteCode, Yhc.TypeCheck
- Invertable desugaring
- Extensive use of the Play class
- Better library story (one library, one file)
- Standalone crossplatform executables
- Fast whole program analysis
- Brand new parsing system
- Untyped Core language (compared to other optimising compilers)
- Simple
So, who wants to have some fun?
Tuesday, December 05, 2006
Generalised Haskell
In the past few days I've been working on a generalised version of Haskell, designed for program optimisation and transformation. I've also implemented the start of a Haskell optimiser, but in about 100 lines of Haskell, using this generalised form of Haskell.
Generalised Haskell is very much like a normal Haskell Core language, with less restrictions in pattern matching. In normal Haskell you would write "map" as:
> map f [] = []
> map f (x:xs) = f x : map f xs
Which would be compiled into:
> map f x = case x of
> ____ [] -> []
> ____ (x:xs) -> f x : map f xs
The rule for pattern matching is that you take the first rule that matches. Generalised Haskell relaxes this slightly to take any one rule that matches, but not necessarily in order. The second relaxation is that when pattern matching on the left hand side, functions can appear as patterns.
For example, you can now define:
> map id x = x
> map f x= case x of
> ____ [] -> []
> ____ (x:xs) -> f x : map f xs
Note that the "map id" case looks very much like GHC's Rules feature. The advantage for optimisation is that many activities can be encoding using these pattern matches - arity raising, specialisation, deforestation.
I am still working on a tool that uses this technique for optimisation, but initial results look quite promising, while the code remains impressively short.
Generalised Haskell is very much like a normal Haskell Core language, with less restrictions in pattern matching. In normal Haskell you would write "map" as:
> map f [] = []
> map f (x:xs) = f x : map f xs
Which would be compiled into:
> map f x = case x of
> ____ [] -> []
> ____ (x:xs) -> f x : map f xs
The rule for pattern matching is that you take the first rule that matches. Generalised Haskell relaxes this slightly to take any one rule that matches, but not necessarily in order. The second relaxation is that when pattern matching on the left hand side, functions can appear as patterns.
For example, you can now define:
> map id x = x
> map f x= case x of
> ____ [] -> []
> ____ (x:xs) -> f x : map f xs
Note that the "map id" case looks very much like GHC's Rules feature. The advantage for optimisation is that many activities can be encoding using these pattern matches - arity raising, specialisation, deforestation.
I am still working on a tool that uses this technique for optimisation, but initial results look quite promising, while the code remains impressively short.
Friday, November 17, 2006
HsInstaller
I've given this message and idea to a few people already, via email and IRC, so I thought maybe I should share it slightly wider and get feedback from people.
I am intending to start a project called HsInstaller, to produce Windows installers for:
Hat, Yhc, WinHugs and any Cabal program (definately Hoogle, hoepfully Happy, Alex, Haddock etc.), maybe GHC and Gtk2Hs if thats possible. This project does NOT hope to create installers for libaries, just standalone executable programs. A wrapper can be produced for libraries that just calls the underlying Cabal infastructure much more easily.
At the moment the Haskell community has several different installers, the C based one I wrote for WinHugs that generates a .exe, and the GHC one you have that generates a .msi, and the Gtk2Hs one that uses InnoSetup. There are advantages and disadvantages to all approaches, but since the world is going steadily towards .msi's that might be the best format to standardise on. Of course, it might not be the best format, discussion is welcome!
Unfortunately the installer code used by GHC is not publically available, one consequence of this is that GHC does not have snapshot installers for Windows, and in fact a GHC release is not prepackaged for Windows - this is something done later.
So, my general thoughts are to try and see if a copy of the GHC installer can be obtained (this is apparently likely in the future). Collect all the installers that everyone uses, sit down with everyone who wants an installer and figure out what we have, and what we want. Once thats done we can start implementing something that everyone can reuse easily.I am intending to start a project called HsInstaller, to produce Windows installers for:
Hat, Yhc, WinHugs and any Cabal program (definately Hoogle, hoepfully Happy, Alex, Haddock etc.), maybe GHC and Gtk2Hs if thats possible. This project does NOT hope to create installers for libaries, just standalone executable programs. A wrapper can be produced for libraries that just calls the underlying Cabal infastructure much more easily.
At the moment the Haskell community has several different installers, the C based one I wrote for WinHugs that generates a .exe, and the GHC one you have that generates a .msi, and the Gtk2Hs one that uses InnoSetup. There are advantages and disadvantages to all approaches, but since the world is going steadily towards .msi's that might be the best format to standardise on. Of course, it might not be the best format, discussion is welcome!
Unfortunately the installer code used by GHC is not publically available, one consequence of this is that GHC does not have snapshot installers for Windows, and in fact a GHC release is not prepackaged for Windows - this is something done later.
Anyone have any thoughts? I have about 4 projects that need installers (Hat, Yhc, WinHugs, Hoogle), but it would be nice if everyone could be satisfied by the results.
Monday, November 13, 2006
Dr Haskell progress
I've been working on Dr Haskell for a little bit, and its now quite a bit cleverer. For those who don't know, Dr Haskell tries to make helpful suggestions about your code. For example, if you use "concat (map f x)", it will suggest you use "concatMap f x". It can also do other clever things, for example:
not (a == b) ===> use /=
if x `elem` xs then True else x == 1 ===> use an or
if bracket then "(" else "" ===> ['(' | bracket]
The idea is to introduce beginners to new functions or patterns of Haskell that they might not have been aware of, without requiring too much thought or learning, until you have identified such an instance. I think of this as a nice complement to Hoogle, since Hoogle caters for the case when beginners have already identified where a common pattern may lie.
Of course, the biggest weakness in Dr Haskell is that it matches at the expression level only, a beginner might write:
takeheads [] = []
takeheads (x:xs) = head x : takeheads xs
(And indeed they do, I've seen that 4 times already today!) An experience programmer would recognise that as a map, and now, so will Dr Haskell! It will report "specialised version of map used as takeheads, line number n".
Some other things that Dr Haskell can now spot:
sum :: [Int] -> Int
sum [] = 0
sum (x:xs) = x + sum xs
(its a foldr, as written above - although I realise foldl' is a better choice for sum)
reverse xs = rev [] xs
where
rev acc [] = acc
rev acc (x:xs) = rev (x:acc) xs
(rev is a foldl)
Dr Haskell can now spot all of these, and has the power to spot lots more patterns using recursion as well as expression matching. I think this could be really helpful for beginners, if anyone has any interesting ideas about this please let me know. I hope to package up a release in the next few days.
not (a == b) ===> use /=
if x `elem` xs then True else x == 1 ===> use an or
if bracket then "(" else "" ===> ['(' | bracket]
The idea is to introduce beginners to new functions or patterns of Haskell that they might not have been aware of, without requiring too much thought or learning, until you have identified such an instance. I think of this as a nice complement to Hoogle, since Hoogle caters for the case when beginners have already identified where a common pattern may lie.
Of course, the biggest weakness in Dr Haskell is that it matches at the expression level only, a beginner might write:
takeheads [] = []
takeheads (x:xs) = head x : takeheads xs
(And indeed they do, I've seen that 4 times already today!) An experience programmer would recognise that as a map, and now, so will Dr Haskell! It will report "specialised version of map used as takeheads, line number n".
Some other things that Dr Haskell can now spot:
sum :: [Int] -> Int
sum [] = 0
sum (x:xs) = x + sum xs
(its a foldr, as written above - although I realise foldl' is a better choice for sum)
reverse xs = rev [] xs
where
rev acc [] = acc
rev acc (x:xs) = rev (x:acc) xs
(rev is a foldl)
Dr Haskell can now spot all of these, and has the power to spot lots more patterns using recursion as well as expression matching. I think this could be really helpful for beginners, if anyone has any interesting ideas about this please let me know. I hope to package up a release in the next few days.
Sunday, November 12, 2006
Library idea: the Safe library
Often Haskell programmers end up with "error, head []" - a totally useless error message!
Because in developing Catch I have 10,000's of lines, that would be a real pain. To combat this I have:
headNote :: String -> [a] -> a
headNote err [] = error $ "headNote, " ++ err
headNote err (x:xs) = x
I also have fromJustNote, lookupJust (fromJust . lookup), assertNote etc - loads of useful safe functions. I also have headMaybe :: [a] -> Maybe a. Perhaps this could be useful as a library - the safe library?
I would imagine lots of functions from the various Prelude/List libraries, some with Note versions taking a parameter to give a better error message, some with Maybe versions to return a Maybe on failure.
Anyone think this would be useful? Its technically trivial to implement, but I don't have enough time to manage this, so perhaps someone else would like to take this one on?
Because in developing Catch I have 10,000's of lines, that would be a real pain. To combat this I have:
headNote :: String -> [a] -> a
headNote err [] = error $ "headNote, " ++ err
headNote err (x:xs) = x
I also have fromJustNote, lookupJust (fromJust . lookup), assertNote etc - loads of useful safe functions. I also have headMaybe :: [a] -> Maybe a. Perhaps this could be useful as a library - the safe library?
I would imagine lots of functions from the various Prelude/List libraries, some with Note versions taking a parameter to give a better error message, some with Maybe versions to return a Maybe on failure.
Anyone think this would be useful? Its technically trivial to implement, but I don't have enough time to manage this, so perhaps someone else would like to take this one on?
Friday, November 10, 2006
System.FilePath, automated testing
I just released System.FilePath, a library for manipulating FilePath's on both Windows and Posix. The problem with a library like this is that there are lots of corner cases, lots of weird situations and everything needs to be tested twice with different semantics. Obviously this requires a test infrastructure different from most other libraries!
I started off with a separate file for writing properties, but quickly found that the properties were the best type of documentation for a function. It was also a pain to keep two different places which identify what the logic of the code is - i.e. the code and the tests. The obvious idea then is to combine the code, documentation and testing into one. Because I am using Haddock that turned out to be quite easy to do - any line beginning with "-- > " is a test. Haddock sees this as monospace formatting, Haskell as comment, and my test generator can find the tests pretty easily.
Within the System.FilePath repo I have a DOS Batch file driver (test.bat) which uses a separate Haskell program (GenTests.hs) to create a test script and run it.
Within the test listing there are some tests which I refer to as constant, and some as properties. Some of the tests have no free variables, these are constant - the GenTests recognises them and outputs them directly - in one execution they either pass or fail. The properties are just standard QuickCheck properties, with the restriction that every multi-letter keyword not in a certain known set is a function in the library, and every variable x..z is a FilePath (hence using a custom FilePath generator).
The main complication in testing from System.FilePath is the fact that every property corresponds to two different tests - one on the Posix implementation, one on the Windows implementation. The translator automatically does this duplication, unless either Posix: or Windows: is given at the start of the test, in which case the test is only executed on the appropriate version.
For QuickCheck testing I defined a FilePath to be a 25 character string, from the following set of characters "?|./:\\abcd 123;_". The idea of this set of characters is to include every character that any aspect of the library treats differently, along with a small selection of "normal" letters/numbers.
There was one modification I had to make to QuickCheck, by default QuickCheck returns successfully outputting success/failure to the console. Unfortunately if an automatic program is executing over 200 tests, then these messages can get obscured in the general noise - this happened more than once. To combat this I defined a new QuickCheck wrapper which calls error on failure. Ideally the signature of quickCheck should be changed to :: .. -> IO Bool to detect these situations and allow the driver script to fail more obviously.
Without QuickCheck I don't think it would have been possible to write the FilePath library - it caught too many obscure bugs that manual testing would never have found. In addition, QuickCheck forced me to think about the properties of the library more closely - I changed some design decisions after it turned out that the properties disagreed with me. The one thing QuickCheck helped with more than anything though was refactoring - despite a massive number of the functions all depending on each other, QuickCheck allows me to change the behaviour of one function in some obscure case and check that no other function was relying on that.
The only criticism that can be levelled at my use of QuickCheck is that failing examples are not minimal, in fact they are exactly 25 characters long. I hope that at some point soon I can make use of SmallCheck (once it has a darcs repo and a .cabal file) to do testing alongside QuickCheck to get a greater depth of coverage.
All the test scripts I have written are available in the darcs repo, under the BSD3. If anyone can make use of them, I'd be happy to have someone take them forward!
I started off with a separate file for writing properties, but quickly found that the properties were the best type of documentation for a function. It was also a pain to keep two different places which identify what the logic of the code is - i.e. the code and the tests. The obvious idea then is to combine the code, documentation and testing into one. Because I am using Haddock that turned out to be quite easy to do - any line beginning with "-- > " is a test. Haddock sees this as monospace formatting, Haskell as comment, and my test generator can find the tests pretty easily.
Within the System.FilePath repo I have a DOS Batch file driver (test.bat) which uses a separate Haskell program (GenTests.hs) to create a test script and run it.
Within the test listing there are some tests which I refer to as constant, and some as properties. Some of the tests have no free variables, these are constant - the GenTests recognises them and outputs them directly - in one execution they either pass or fail. The properties are just standard QuickCheck properties, with the restriction that every multi-letter keyword not in a certain known set is a function in the library, and every variable x..z is a FilePath (hence using a custom FilePath generator).
The main complication in testing from System.FilePath is the fact that every property corresponds to two different tests - one on the Posix implementation, one on the Windows implementation. The translator automatically does this duplication, unless either Posix: or Windows: is given at the start of the test, in which case the test is only executed on the appropriate version.
For QuickCheck testing I defined a FilePath to be a 25 character string, from the following set of characters "?|./:\\abcd 123;_". The idea of this set of characters is to include every character that any aspect of the library treats differently, along with a small selection of "normal" letters/numbers.
There was one modification I had to make to QuickCheck, by default QuickCheck returns successfully outputting success/failure to the console. Unfortunately if an automatic program is executing over 200 tests, then these messages can get obscured in the general noise - this happened more than once. To combat this I defined a new QuickCheck wrapper which calls error on failure. Ideally the signature of quickCheck should be changed to :: .. -> IO Bool to detect these situations and allow the driver script to fail more obviously.
Without QuickCheck I don't think it would have been possible to write the FilePath library - it caught too many obscure bugs that manual testing would never have found. In addition, QuickCheck forced me to think about the properties of the library more closely - I changed some design decisions after it turned out that the properties disagreed with me. The one thing QuickCheck helped with more than anything though was refactoring - despite a massive number of the functions all depending on each other, QuickCheck allows me to change the behaviour of one function in some obscure case and check that no other function was relying on that.
The only criticism that can be levelled at my use of QuickCheck is that failing examples are not minimal, in fact they are exactly 25 characters long. I hope that at some point soon I can make use of SmallCheck (once it has a darcs repo and a .cabal file) to do testing alongside QuickCheck to get a greater depth of coverage.
All the test scripts I have written are available in the darcs repo, under the BSD3. If anyone can make use of them, I'd be happy to have someone take them forward!
Thursday, October 26, 2006
Hat+Windows, 1 happy user!
I just got an email:
"I've got hat-observe working on my code, which makes me very happy."
This is a happy Hat user, who is using my Windows port. As far as I know, this is the first Hat user on Windows who has actually got a real project going through which they really want to debug - not just test stuff.
This makes me very happy too :)
"I've got hat-observe working on my code, which makes me very happy."
This is a happy Hat user, who is using my Windows port. As far as I know, this is the first Hat user on Windows who has actually got a real project going through which they really want to debug - not just test stuff.
This makes me very happy too :)
Saturday, October 21, 2006
30% faster than GHC!
I have been working on a back end to my analysis framework Catch for a while, I do lots of transformations as part of Catch, some of which speed up the code, so hooking a back end up seems sensible. Using this back end, I can be 30% faster than GHC.
Before I show any pretty graphs, there are few big and important disclaimers:
And so on to some pretty graphs of *HC vs GHC on the prime number benchmark:
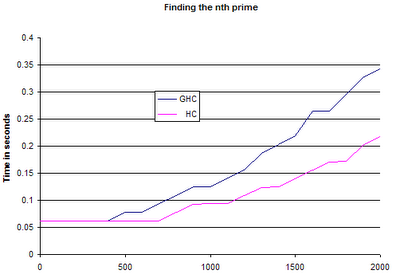
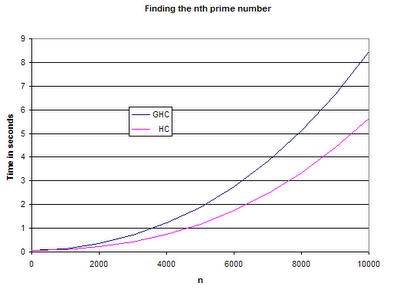
These numbers show a pretty much one third increase in speed.
One of my future tasks is to hook this directly up to a code generator, and hopefully my speed will increase even further - at the moment I have to add things in to make the output valid Haskell which slows down the generated code. A custom back end would help with this, plus I have other techniques for speeding up the back end given some of the "knowledge" accumulated by Catch. I am reasonably confident that GHC is not doing too much of the heavy work when compiling my code, as compiling without any optimisation does not penalise my GHC output too much.
How do I get fast code?
I take the Yhc compiler, and generate Yhc.Core. I take all the Core generated for all bits in the program and splat them together, including the Prelude etc. I run some analysis passes on this code, including making the code completely first order, a little bit of deforestation and a touch of partial evaluation. I then output Haskell, however my Core language is not a subset of Haskell, so some additional things need to be handled.
Will this only work for Primes?
Hopefully not! In theory the back end is general purpose, and should work for anything. In practice, I'm still working on it, and not everything is finished yet.
Whole program analysis? Thats slow!
Not really, I develop Catch in Hugs, it takes around 10 seconds to compile Primes in Hugs, using an entirely unoptimised pipeline - I even use associative lists for function name lookup - and still the performance is not too bad. Only a very small number of the steps I perform are whole program, and the ones that are only get done once in a linear fasion. It probably won't scale to "a whole compiler", but it can certainly hit 1000 line programs with no issue.
What's next?
Stop getting distracted by developing a compiler, and get back to my PhD!
Before I show any pretty graphs, there are few big and important disclaimers:
- I use GHC as a back end
- This means that GHC optimises my code as well!
- Benchmarked against GHC 6.4.2, using -O2
- Only tested on one single file! Prime numbers, from the nofib suite.
- All experiments run on a P4, 3GHz
- All experiments run 5 times, and the lowest number recorded
- I do whole program analysis
And so on to some pretty graphs of *HC vs GHC on the prime number benchmark:
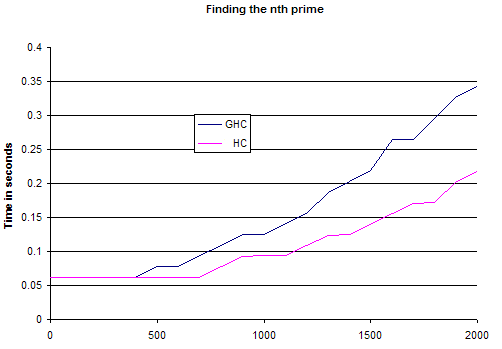
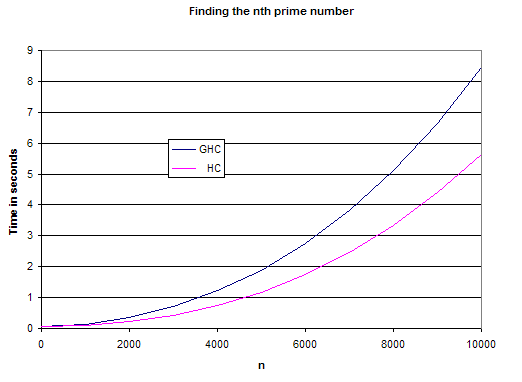
These numbers show a pretty much one third increase in speed.
One of my future tasks is to hook this directly up to a code generator, and hopefully my speed will increase even further - at the moment I have to add things in to make the output valid Haskell which slows down the generated code. A custom back end would help with this, plus I have other techniques for speeding up the back end given some of the "knowledge" accumulated by Catch. I am reasonably confident that GHC is not doing too much of the heavy work when compiling my code, as compiling without any optimisation does not penalise my GHC output too much.
How do I get fast code?
I take the Yhc compiler, and generate Yhc.Core. I take all the Core generated for all bits in the program and splat them together, including the Prelude etc. I run some analysis passes on this code, including making the code completely first order, a little bit of deforestation and a touch of partial evaluation. I then output Haskell, however my Core language is not a subset of Haskell, so some additional things need to be handled.
Will this only work for Primes?
Hopefully not! In theory the back end is general purpose, and should work for anything. In practice, I'm still working on it, and not everything is finished yet.
Whole program analysis? Thats slow!
Not really, I develop Catch in Hugs, it takes around 10 seconds to compile Primes in Hugs, using an entirely unoptimised pipeline - I even use associative lists for function name lookup - and still the performance is not too bad. Only a very small number of the steps I perform are whole program, and the ones that are only get done once in a linear fasion. It probably won't scale to "a whole compiler", but it can certainly hit 1000 line programs with no issue.
What's next?
Stop getting distracted by developing a compiler, and get back to my PhD!
Thursday, September 21, 2006
DriFT
I tried out DriFT recently, and was most impressed, it has the feel of a program that hasn't had much love recently, but thats ok, its still a very useful program.
Firstly there is no easy way to compile it on Windows - its not hard, its just not obvious either. For reference the steps are 1) cd src, 2) ren Version.hs.in Version.hs, 3) ghc --make Drift.hs. For those Windows users who don't want to do that, I've shoved up a binary on my Windows distribution page. Its certainly not hard, but its not as easy as Cabal based thingies.
Once you've done that, "drift -r File.hs" produces the goods, in a very straight forward way. What I wanted was a deriving Binary, with a loadBinary and a saveBinary interface. DriFT offers two separate binary output modes, Binary and GhcBinary - I wanted to use it in Hugs, but a bit of experimentation showed that GhcBinary has a nicer output, so I jumped with that. Once thats done I wanted to combine it with the Binary library to do the actual serialisation - there is one in the repo but it seems to have not been given the attention it needs, so was easier to write my own. See this file in the Yhc repo for how I did it - the answer is not very nicely, but quite workable.
With all this done, now Yhc spits out Core in binary, but more importantly my PhD program now has binary cache's - changing some operations from 30 seconds to 2 seconds, which is nice :)
Firstly there is no easy way to compile it on Windows - its not hard, its just not obvious either. For reference the steps are 1) cd src, 2) ren Version.hs.in Version.hs, 3) ghc --make Drift.hs. For those Windows users who don't want to do that, I've shoved up a binary on my Windows distribution page. Its certainly not hard, but its not as easy as Cabal based thingies.
Once you've done that, "drift -r File.hs" produces the goods, in a very straight forward way. What I wanted was a deriving Binary, with a loadBinary and a saveBinary interface. DriFT offers two separate binary output modes, Binary and GhcBinary - I wanted to use it in Hugs, but a bit of experimentation showed that GhcBinary has a nicer output, so I jumped with that. Once thats done I wanted to combine it with the Binary library to do the actual serialisation - there is one in the repo but it seems to have not been given the attention it needs, so was easier to write my own. See this file in the Yhc repo for how I did it - the answer is not very nicely, but quite workable.
With all this done, now Yhc spits out Core in binary, but more importantly my PhD program now has binary cache's - changing some operations from 30 seconds to 2 seconds, which is nice :)
Wednesday, September 06, 2006
Hoogle mailing list
There is now a hoogle mailing list: http://www.haskell.org/mailman/listinfo/hoogle
So instead of emailing me individually, or talking to me on IRC, instead you can just email that list and hopefully others can give useful feedback as well.
So instead of emailing me individually, or talking to me on IRC, instead you can just email that list and hopefully others can give useful feedback as well.
Friday, September 01, 2006
Over 65,000 Hoogle Searches!
I just checked the Hoogle logs, and found a stagering 67,112 searches have been performed.
18495 of these searches were for different terms, people searched for "map" 4036. Thats quite a lot of searching!
I think those logs are since about October, which makes this just under a years data. I have no idea of what the breakdown over time is, but Hoogle 4 will have better logging, and should be able to tell me.
Update: dons tells me there have been 3849 lambdabot @hoogle searches
18495 of these searches were for different terms, people searched for "map" 4036. Thats quite a lot of searching!
I think those logs are since about October, which makes this just under a years data. I have no idea of what the breakdown over time is, but Hoogle 4 will have better logging, and should be able to tell me.
Update: dons tells me there have been 3849 lambdabot @hoogle searches
Wednesday, August 23, 2006
Parsec and Hoogle
For the last few days I've been rewritting the parsing in Hoogle to use parsec. As an end result, the parser is a lot more powerful, and more maintainable, and extendable - on the downside its longer and more complex.
The thing that most impressed me about parsec was its compositionality. In Hoogle there are type signatures, which are both on database lines (map :: (a -> b) -> [a] -> [b]), and there are user queries which might have a type signature in them, amongst other junk. Thanks to parsec I can use the same type signature parser in both of them, with extensions for the relevant bits. I couldn't really do this with a traditional yacc/bison/happy parser generator. Its also great for the fuzzy nature of user searches - you don't want to parse error if there is any sensible user interpretation of what they wrote.
Thanks to this rewrite, I now get a few query goodies that I always wanted but could never properly parse. Included in this are multiple words "concat map", names and type signatures "map :: [a] -> [a]" and the search parser now checks for command line options, which stops the bugs with things like "->" being misinterpretted.
The thing that most impressed me about parsec was its compositionality. In Hoogle there are type signatures, which are both on database lines (map :: (a -> b) -> [a] -> [b]), and there are user queries which might have a type signature in them, amongst other junk. Thanks to parsec I can use the same type signature parser in both of them, with extensions for the relevant bits. I couldn't really do this with a traditional yacc/bison/happy parser generator. Its also great for the fuzzy nature of user searches - you don't want to parse error if there is any sensible user interpretation of what they wrote.
Thanks to this rewrite, I now get a few query goodies that I always wanted but could never properly parse. Included in this are multiple words "concat map", names and type signatures "map :: [a] -> [a]" and the search parser now checks for command line options, which stops the bugs with things like "->" being misinterpretted.
Thursday, August 17, 2006
Neil vs Cabal
Today I've been trying to get into cabal, since it seems a pretty cool thing, and it looks like the way forward.
As I've been doing this, trying to compile various projects using Cabal, it turns out that I spent all day encountering bugs! I've hit things that seem a bit curious in loads of programs, sent off patches, reported bugs, asked for clarification etc. Hopefully this will be fixed at some point soon, after enough people have bashed through it.
In particular, to try and get this going better, I'm going to try and keep the HEAD versions of various projects compiled regularly with Cabal on Windows - and then probably distribute the binaries as part of my Haskell on Windows drive.
I'm also trying to get Hoogle working properly with Cabal, since thats going to be the future way of building it, probably.
Which brings me on to a final question about the Hoogle license, what should it be? Currently Hoogle is licensed under Creative Commons Attribution-NonCommercial-ShareAlike License. Nothing else in the Haskell world is, so its not particularly sensible that Hoogle is. My basic thoughts are GPL vs BSD. What do people think one way or the other?
As I've been doing this, trying to compile various projects using Cabal, it turns out that I spent all day encountering bugs! I've hit things that seem a bit curious in loads of programs, sent off patches, reported bugs, asked for clarification etc. Hopefully this will be fixed at some point soon, after enough people have bashed through it.
In particular, to try and get this going better, I'm going to try and keep the HEAD versions of various projects compiled regularly with Cabal on Windows - and then probably distribute the binaries as part of my Haskell on Windows drive.
I'm also trying to get Hoogle working properly with Cabal, since thats going to be the future way of building it, probably.
Which brings me on to a final question about the Hoogle license, what should it be? Currently Hoogle is licensed under Creative Commons Attribution-NonCommercial-ShareAlike License. Nothing else in the Haskell world is, so its not particularly sensible that Hoogle is. My basic thoughts are GPL vs BSD. What do people think one way or the other?
Wednesday, August 16, 2006
Hoogle 4 plans
After spending about the last 3 months replying to most people's Hoogle comments with "that will be fixed in Hoogle 4", its about time I actually implement Hoogle 4. Just to give people an idea of where I'm going, I thought I'd summarise what Hoogle 4 means to me :)
First off, I abandoned .ths after talking with Niklas who does Haskell-source-exts and HSP, and will be using his stuff. Its got advantages of tag safety and a better syntax, lacks a few bits, but being written by someone else saves me a bit of work. Its also well supported, something thats essential!
Anyway, the plans for Hoogle 4 fall into a few areas:
No bugs: type classes, type aliases, higher kinded type classes - all these things confuse Hoogle. Either they are bugs, or they come close enough to count as them. These will all be fixed.
Help the user: searching for ThreadID doesn't work (its ThreadId), searching for Just a doesn't work, searching for Maybe -> Int doesn't work, all just fail silently. I want to tell people when they are searching a bit dubiously and fix it for them.
Do what users keep asking for: often users do searches for multiple words, "map concat", this currently gives them very confusing results (the type "m a" is equivalent).
Be a database: I want to give more database like features, lookup Just will give you the functions that use it.
Faster: I want to make text searching 100's of times faster, which isn't so the results come back faster but so that...
Packages: I want to be able to search packages other than the default ones, such as Gtk2hs (which you can already Hoogle search), and lots lots more. Which requires a speed boost.
AJAX: I have a few good AJAX ideas for making searching just a little bit quicker.
Lots to do, and will probably be an entire rewrite (again...), but this is hopefully going to be the version that sticks arond for a very long time and comes out of Beta.
First off, I abandoned .ths after talking with Niklas who does Haskell-source-exts and HSP, and will be using his stuff. Its got advantages of tag safety and a better syntax, lacks a few bits, but being written by someone else saves me a bit of work. Its also well supported, something thats essential!
Anyway, the plans for Hoogle 4 fall into a few areas:
No bugs: type classes, type aliases, higher kinded type classes - all these things confuse Hoogle. Either they are bugs, or they come close enough to count as them. These will all be fixed.
Help the user: searching for ThreadID doesn't work (its ThreadId), searching for Just a doesn't work, searching for Maybe -> Int doesn't work, all just fail silently. I want to tell people when they are searching a bit dubiously and fix it for them.
Do what users keep asking for: often users do searches for multiple words, "map concat", this currently gives them very confusing results (the type "m a" is equivalent).
Be a database: I want to give more database like features, lookup Just will give you the functions that use it.
Faster: I want to make text searching 100's of times faster, which isn't so the results come back faster but so that...
Packages: I want to be able to search packages other than the default ones, such as Gtk2hs (which you can already Hoogle search), and lots lots more. Which requires a speed boost.
AJAX: I have a few good AJAX ideas for making searching just a little bit quicker.
Lots to do, and will probably be an entire rewrite (again...), but this is hopefully going to be the version that sticks arond for a very long time and comes out of Beta.
Sunday, August 13, 2006
.ths (Textual Haskell Source)
I've been doing some work on Hoogle 4 over the last week while I've been away from a computer. Lots of cool new ideas, some paper code, and other goodies - will probably be a few weeks before I start to crank out implementations and improvements get seen on the main Hoogle site, and perhaps 2 or 3 months before Hoogle 4 starts to take shape.
Anyway, one thing Hoogle needs to do is to output a web page, and at the moment it does that by reading in text files, and writing them out. To do a typical search page it shoves out a standard prefix, a top bit, the answers and a suffix. Only the answers are generated on the fly, the others are included in. Of course, this means that the HTML is in 4 places, and the reusability is poor (files are chunks of text, not functions). The pages also have small tweaks to them based on dynamic data - for example the title of the page is the search query. To accomodate this I had to add $ replacement, so $ becomes the search query. Messy, and not very general.
So to answer all this, I devised .ths - Textual Haskell Source. Currently you have .hs (source code is the main thing), .lhs (comments are the main thing) and now you have .ths (text is the main thing). Lets start with an example:
> showHtml :: String -> String
> showHtml search = pure
[html]
[head]
[title]<% search %> - Hoogle[/title]
[/head]
Note that in this example I am escaping the code (with > ticks), and the text is just the main bit. I also have <% code %> which is substituted inline.
I can also do more advanced things (naturally)
> showList :: FilePath -> [Bool] -> IO String
> showList filename items =
> src <- readFile filename
The length of <% filename %> is <% length src %>
And the booleans are
<%for i = items %> <%if i %>ON<%else%>off<%end if%><%end for%>
I have all these bits implemented, and hope to make a release in a few days. I kind of have to release, because the current darcs version of Hoogle will be using them in a few days anyway.
And of course, since all this stuff is Haskell, its easier to compose, call as functions, etc.
Thoughts or comments?
Anyway, one thing Hoogle needs to do is to output a web page, and at the moment it does that by reading in text files, and writing them out. To do a typical search page it shoves out a standard prefix, a top bit, the answers and a suffix. Only the answers are generated on the fly, the others are included in. Of course, this means that the HTML is in 4 places, and the reusability is poor (files are chunks of text, not functions). The pages also have small tweaks to them based on dynamic data - for example the title of the page is the search query. To accomodate this I had to add $ replacement, so $ becomes the search query. Messy, and not very general.
So to answer all this, I devised .ths - Textual Haskell Source. Currently you have .hs (source code is the main thing), .lhs (comments are the main thing) and now you have .ths (text is the main thing). Lets start with an example:
> showHtml :: String -> String
> showHtml search = pure
[html]
[head]
[title]<% search %> - Hoogle[/title]
[/head]
Note that in this example I am escaping the code (with > ticks), and the text is just the main bit. I also have <% code %> which is substituted inline.
I can also do more advanced things (naturally)
> showList :: FilePath -> [Bool] -> IO String
> showList filename items =
> src <- readFile filename
The length of <% filename %> is <% length src %>
And the booleans are
<%for i = items %> <%if i %>ON<%else%>off<%end if%><%end for%>
I have all these bits implemented, and hope to make a release in a few days. I kind of have to release, because the current darcs version of Hoogle will be using them in a few days anyway.
And of course, since all this stuff is Haskell, its easier to compose, call as functions, etc.
Thoughts or comments?
Friday, July 07, 2006
Haskell debugging with Hat on Windows
For the last couple of days I've been trying to get Hat working on Windows. I now have over half the tools working on Windows, and have a bundle ready for Windows users to install: http://www.cs.york.ac.uk/fp/temp/hat-win32-05_jul_2006.zip
How to install: Extract the contents of the .zip file into a folder preserving
directory structure. Add the folder containing hat-make to your %PATH% variable, this is
100% required, even if you give the explicit path to hat-make when you
use it. Make sure ghc is available on your system and has been added to the %PATH%.
How to use: cd to the directory containing your Haskell source
hat-make Main.hs
main
hat-stack Main.hat
hat-observe Main.hat
I am also working on a graphical user interface for these tools, a screenshot is here, using Gtk2Hs. - its not ready yet, but hopefully soon.
If any Windows users try this out and find that it either works or does not, please let me know.
How to install: Extract the contents of the .zip file into a folder preserving
directory structure. Add the folder containing hat-make to your %PATH% variable, this is
100% required, even if you give the explicit path to hat-make when you
use it. Make sure ghc is available on your system and has been added to the %PATH%.
How to use: cd to the directory containing your Haskell source
hat-make Main.hs
main
hat-stack Main.hat
hat-observe Main.hat
I am also working on a graphical user interface for these tools, a screenshot is here, using Gtk2Hs. - its not ready yet, but hopefully soon.
If any Windows users try this out and find that it either works or does not, please let me know.
Thursday, June 29, 2006
Haskell Suggest
Often a more experienced Haskell user can point out some clever trick in some Haskell code that a beginner may not know about, for example:
Often this is because the new user is unfamiliar with the existance of a particular function, of course they can Hoogle it, if they thought it might exist, but often it never occurs to them.
The solution is Haskell Suggest, have a tool that automatically spots and suggests these things. I think the best implementation would be using Yhc Core for a couple of reasons, its relatively unmodified (no advanced transformations like inlining), has source positions and is simple.
Sounds like a good idea to go and implement.... Credits to dons for discussing this on Haskell IRC.
- concat (map f x)
- map g (map f x)
- putStr . (++) "\n"
Often this is because the new user is unfamiliar with the existance of a particular function, of course they can Hoogle it, if they thought it might exist, but often it never occurs to them.
The solution is Haskell Suggest, have a tool that automatically spots and suggests these things. I think the best implementation would be using Yhc Core for a couple of reasons, its relatively unmodified (no advanced transformations like inlining), has source positions and is simple.
Sounds like a good idea to go and implement.... Credits to dons for discussing this on Haskell IRC.
Wednesday, June 21, 2006
Hoogle improvements
I have been making some improvements to Hoogle - nothing to do with the actual searching engine, but lots of tweaks to the page layout. Its now less cluttered, and has less pointless pages, and has a good link to a Firefox plugin. I have also moved all the documentation into the wiki, so hopefully other people will be able to contribute.
I'm still looking for a nice logo if anyone has any artistic talent - I certainly don't!
I'm still looking for a nice logo if anyone has any artistic talent - I certainly don't!
Monday, June 12, 2006
Windows and Haskell
I have decided to start the Haskell on Windows software repository, its located here:
http://www-users.cs.york.ac.uk/~ndm/projects/windows.php
The idea is that Linux users can use their relevant package manager and in one click do "emerge ghc" or something and get GHC installed quickly and easily. For Windows users this means downloading either a .zip or an installer of the project quickly and directly.
The page above just links directly to the most appropriate installation file, and is going to be kept up to date with new versions.
Its kind of depressing to see how few precompiled Windows binaries there are for Haskell programs - only 8, and I compiled 3 of them myself. If anyone has a Haskell project and would like a Windows build contributing please email me, and I'll make a binary and add it to that list.
http://www-users.cs.york.ac.uk/~ndm/projects/windows.php
The idea is that Linux users can use their relevant package manager and in one click do "emerge ghc" or something and get GHC installed quickly and easily. For Windows users this means downloading either a .zip or an installer of the project quickly and directly.
The page above just links directly to the most appropriate installation file, and is going to be kept up to date with new versions.
Its kind of depressing to see how few precompiled Windows binaries there are for Haskell programs - only 8, and I compiled 3 of them myself. If anyone has a Haskell project and would like a Windows build contributing please email me, and I'll make a binary and add it to that list.
Monday, June 05, 2006
The Play class
One useful trick I've found when manipulating data structures is the Play class, which I created to "play" with various data structures. Often a data structure will contain the same type within it - for example:
data Expr = Sum [Expr]
| Literal Int
| Div Expr Expr
Now I define a Play class as:
class PlayExpr a where
mapExpr :: (Expr -> Expr) -> a -> a
allExpr :: a -> [Expr]
mapExpr just maps over every element in the data structure, and allExpr gives every element back, this makes lots of things quite easy.
For example, with these properties you can test if there are any negative literals in the list:
[n | Literal n <- allExpr x, n < 0]
And operations like replacing Sum [x] with x can be coded easily as follows:
mapExpr f x
where
f (Sum [x]) = x
f x = x
This could be done as just two functions, not in a class, but by putting it in a class you can add instances for [x] (a,b) etc. And also, if this expression is embeded in a larger data structure, you can then traverse that larger data structure in exactly the same way.
I have used this quite extensively in some of my code.
data Expr = Sum [Expr]
| Literal Int
| Div Expr Expr
Now I define a Play class as:
class PlayExpr a where
mapExpr :: (Expr -> Expr) -> a -> a
allExpr :: a -> [Expr]
mapExpr just maps over every element in the data structure, and allExpr gives every element back, this makes lots of things quite easy.
For example, with these properties you can test if there are any negative literals in the list:
[n | Literal n <- allExpr x, n < 0]
And operations like replacing Sum [x] with x can be coded easily as follows:
mapExpr f x
where
f (Sum [x]) = x
f x = x
This could be done as just two functions, not in a class, but by putting it in a class you can add instances for [x] (a,b) etc. And also, if this expression is embeded in a larger data structure, you can then traverse that larger data structure in exactly the same way.
I have used this quite extensively in some of my code.
Saturday, May 27, 2006
Abusing Haskell for fun and profit
At the moment I am working on a System.FilePath module combining Lemmih's one from cabal, and the one from Yhc. In order to do this I have had to abuse Monad's to the extreme (instance Monad Test) and CPP to the extreme (#define module --). Hopefully the result will be useful to a large number of people, and might even make it into base. [Note: the interface to System.FilePath is unstable, and will change - if you have any suggestions please let me know!]
I have also been advocating Haskell to my research group, to the stage where in my group there is only one hold out Python programmer, and everyone else has moved to Haskell even for non-Haskell related projects/PhD's. Now I have to start trying to persuade them to move to Windows...
I have also been advocating Haskell to my research group, to the stage where in my group there is only one hold out Python programmer, and everyone else has moved to Haskell even for non-Haskell related projects/PhD's. Now I have to start trying to persuade them to move to Windows...
Tuesday, May 16, 2006
WinHugs release
A release of WinHugs has just gone out:
http://cvs.haskell.org/Hugs/pages/downloading-May2006.htm
This is the first released final Haskell software I have contributed to!
For Windows users, this should be an essential upgrade - an entirely rewritten WinHugs, updated libraries, FFI that works with Visual Studio and lots of other goodies.
http://cvs.haskell.org/Hugs/pages/downloading-May2006.htm
This is the first released final Haskell software I have contributed to!
For Windows users, this should be an essential upgrade - an entirely rewritten WinHugs, updated libraries, FFI that works with Visual Studio and lots of other goodies.
Saturday, April 29, 2006
Windows and Haskell
I use Haskell on Windows, and I always tend to feel like a second class citizen... Lots of things just don't work as well on Windows as compared to Linux with Haskell tools - for instance, there is no hmake for Windows, nhc never worked on Windows, ghc ships with something close to a linux distribution with Windows, I once read the instructions to build ghc on windows and I cried, to make the standard libraries for Haskell its pretty much Linux, or something terrible like MSYS or Cygwin - the list goes on...
The reason I'm complaining is that I've been working on getting hugs and FFI working on Windows, the actual Windows code is all relatively easy, but trying to get the base package to compile on Windows seems not possible. Since the base package also compiles FFI .dll's, these are also built in MSYS with GCC. Hopefully in the future Cabal will come to the rescue, but at the moment I'm still not convinced - first off Cabal seems to match the way Linux users think, and not Windows users in any way. Although at the same time, it does seem quite impressive, and the way out for the future.
Hopefully, one day everyone will see the light and stop using Linux, move to Windows, and we can all have nice user interfaces and nice programming languages in one package.
--
Just a quick note, I really am very greatful for all the projects that have Windows ports,
I just hit my head against a brick wall every time I see a makefile :)
The reason I'm complaining is that I've been working on getting hugs and FFI working on Windows, the actual Windows code is all relatively easy, but trying to get the base package to compile on Windows seems not possible. Since the base package also compiles FFI .dll's, these are also built in MSYS with GCC. Hopefully in the future Cabal will come to the rescue, but at the moment I'm still not convinced - first off Cabal seems to match the way Linux users think, and not Windows users in any way. Although at the same time, it does seem quite impressive, and the way out for the future.
Hopefully, one day everyone will see the light and stop using Linux, move to Windows, and we can all have nice user interfaces and nice programming languages in one package.
--
Just a quick note, I really am very greatful for all the projects that have Windows ports,
I just hit my head against a brick wall every time I see a makefile :)
Tuesday, April 25, 2006
Hoogle Logo
I just got an email from someone pointing out that the Hoogle logo might be infringing Google's copyright or trademark. He might be right, he might not, but I think Hoogle is getting to the stage where I probably need to change the logo to something less like Google. If anyone has any ideas, I'd be happy to see them. I just want something vector based (SVG or Xara or something else) that looks nice and is essentially the word "Hoogle" with a lambda for the l, in reasonably clear writing. Fades, gradients, transparencies, textures are all fine.
I've just filled out a report on Hoogle for the HCAR, including some light plans for the future. It seems that between every HCAR I release a new version and rewrite the existing version, and never make a release. I'll try to change that before the next one.
The future plans for Hoogle are to make it go faster, and once that happens I can add loads more libraries and applications into the search. I also want to fix a few remaining bugs (nothing is considered a Monad due to higher kinds), and add a few features that never got finished (type aliasing). I also want searching for multiple words, since it seems a lot of people do that, and currently Hoogle considers it a type search. If anyone did want to do any work on it, there is plenty there, and I'm happy to accept patches :)
With all those fixes, I want the following searches to be "better":
And I want the following searches to have better error messages:
I've just filled out a report on Hoogle for the HCAR, including some light plans for the future. It seems that between every HCAR I release a new version and rewrite the existing version, and never make a release. I'll try to change that before the next one.
The future plans for Hoogle are to make it go faster, and once that happens I can add loads more libraries and applications into the search. I also want to fix a few remaining bugs (nothing is considered a Monad due to higher kinds), and add a few features that never got finished (type aliasing). I also want searching for multiple words, since it seems a lot of people do that, and currently Hoogle considers it a type search. If anyone did want to do any work on it, there is plenty there, and I'm happy to accept patches :)
With all those fixes, I want the following searches to be "better":
- Monad a => [a b] -> a [b]
- zip with
- [Char] -> String
And I want the following searches to have better error messages:
- Just a -> a
- Maybe -> a
Saturday, April 15, 2006
My Haskell related projects
Just for general information, I am involved in the following Haskell projects:
As author:
Hoogle - a Haskell search engine
Catch - a safety checker for Haskell (my PhD)
WinHaskell - A GUI for Haskell use on Windows
WinHugs - the GUI bit of Hugs (I rewrote the old WinHugs from scratch)
As a major contributor:
Yhc - the York Haskell compiler, I do the -core stuff, and other related bits.
And have submitted patches to:
Haddock - Add hoogle output
GHCi - :set prompt feature
Hugs - :main support (which is now in GHCi as well, thanks to someone else)
What do all the projects that I am mainly working on have in common? None have ever had an official release. Hoogle is approaching version 4 without having ever left beta, WinHaskell is just basically functional but definately not finished, Catch is coming along but far away from end user use, WinHugs is pretty much done, just release work remaining really.
At the moment I'm focused on WinHaskell, my progress can be tracked roughly here, but there are about 10 additional patches on my computer and I'm currently working on number 11.
As author:
Hoogle - a Haskell search engine
Catch - a safety checker for Haskell (my PhD)
WinHaskell - A GUI for Haskell use on Windows
WinHugs - the GUI bit of Hugs (I rewrote the old WinHugs from scratch)
As a major contributor:
Yhc - the York Haskell compiler, I do the -core stuff, and other related bits.
And have submitted patches to:
Haddock - Add hoogle output
GHCi - :set prompt feature
Hugs - :main support (which is now in GHCi as well, thanks to someone else)
What do all the projects that I am mainly working on have in common? None have ever had an official release. Hoogle is approaching version 4 without having ever left beta, WinHaskell is just basically functional but definately not finished, Catch is coming along but far away from end user use, WinHugs is pretty much done, just release work remaining really.
At the moment I'm focused on WinHaskell, my progress can be tracked roughly here, but there are about 10 additional patches on my computer and I'm currently working on number 11.
Friday, April 14, 2006
Planet Haskell
I thought I'd turn this blog into one for my Haskell related stuff, since i doubt my friends in real life want to hear lots about Haskell, and I doubt Haskell people want to hear about me getting drunk and ranting about the world.
Just a few links for the first Haskell related post:
Planet Haskell - http://planet.haskell.org/
My academic website - http://www.cs.york.ac.uk/~ndm/
Just a few links for the first Haskell related post:
Planet Haskell - http://planet.haskell.org/
My academic website - http://www.cs.york.ac.uk/~ndm/
Subscribe to:
Posts (Atom)
